Rád bych vám v následujícím článku přiblížil řešení, které se zaměřuje na performance monitoring vámi zvolených aplikací a služeb. Jedná se o ucelený systém propojení několika nástrojů, které následně slouží k vyhodnocení náročnosti jednotlivých procesů a také jejich přehledném zobrazení v Grafaně. Veškeré prvky vám postupně popíši a přiblížím.
Posláním tohoto článku tedy není pouze nastínit celou problematiku ale také pomoci s vlastní realizací kompletního řešení. To bude umět nejen monitorovat zátěž systému, ale i vizualizovat ji v grafu s možností zpětně dohledat, jak se celý systém chová a jak je na tom s “konzumací” hardwarových prostředků.
Celé řešení se skládá ze tří prvků, resp. aplikací: Telegraf, InfluxDB a Grafana.
Popis aplikací
Telegraf
Nejdůležitějším prvkem, který je jádrem celého řešení je Telegraf. Jde o službu (agenta), která nám umožňuje sběr výkonnostních dat a metrik ze systému, na kterém je spuštěna.
Dokáže monitorovat libovolné služby a procesy, které na tomto systému běží. Veškerá sesbíraná data jsou ukládána jako „time series data“ a následně ukládána do databáze. Telegraf umožňuje ukládat data do různých typů uložišť. V našem případě využíváme ukládání do InfluxDB, o které se zmíním později.
Samotný Telegraf je navržen tak, aby způsobil minimální paměťové zatížení systému (počítače), na kterém běží, ale zároveň vývojářům poskytl široké spektrum služeb a rozhraní, se kterými je schopen komunikovat.
Telegraf je tedy šikovný pomocník, který nám pomůže získat metriky ze sledovaných procesů a následně je uložit do databáze InfluxDB. Dokáže však také monitorovat i různá data z databázových systému, HW senzorů, IoT senzorů apod.
InfluxDB
Jedná se o databázi, která je určena pro sběr časově uspořádaných dat (time series data). Řešení je navrženo tak, aby umožňovalo velmi rychlý zápis nasbíraných dat. Zároveň také – pochopitelně – umožňuje i jejich velmi rychlé čtení.
Grafana
Abychom měli úvod ucelený, zmíním ještě poslední část celého řešení, a tím je Grafana.
Grafana je open source nástroj, který slouží k vizualizaci nasbíraných metrik a analytických dat. Nejčastěji se používá právě k vizualizaci časových řad, ale využívá se také v dalších oblastech, včetně průmyslových senzorů, IoT, senzorů počasí apod.
Jejímu podrobnějšímu popisu a nastavení se budeme věnovat později.
Instalace InfluxDB
Před nastavením a instalací jakéhokoli monitorovacího agenta je důležité mít nejprve připravenou „time series“ databázi pro sběr dat, bez které by celý systém nebyl kompletní, tedy funkční. Jak bylo uvedeno výše, použijeme InfluxDB.
Pojďme se tedy v krátkosti podívat na samotnou instalaci a konfiguraci:
Instalace a vytvoření databáze
Instalace InfluxDB není náročná a jako obvykle začíná stažením binárních souborů. Například verzi 1.8 naleznete zde. Stažený soubor .zip uložte a rozbalte do svého počítače.
Spusťte příkazový řádek a přejděte do složky, kde jste uložili binární soubory (v mém případě přímo Program Files). V ní pak uvidíte několik souborů:
- influx.exe: spustitelný soubor CLI používaný pro snadnou navigaci v databázích a měření
- influxd.exe: používá se ke spuštění instance InfluxDB v počítači
- influx_stress.exe: spustitelný soubor používaný ke spuštění zátěžových testů v počítači;
- influx_inspect: používá se ke kontrole disků a InfluxDB (v našem případě jej nepoužíváme).
- Influxdb.conf: konfigurační soubor
V našem případě chceme spustit soubor influxd (C:\Program Files\influxdb>influxd.exe). Jakmile uvidíme následující, je vše v pořádku.
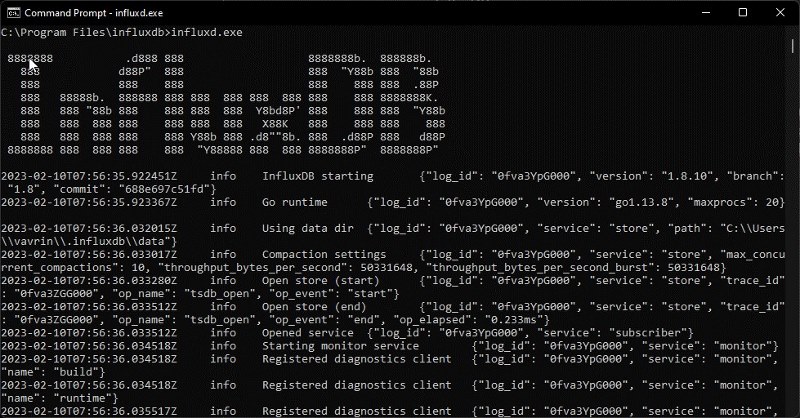
Jakmile nám tedy v počítači běží instance influxDB , pomocí souboru influx.exe spustíme relaci Power Shellu s otevřeným připojením k naší instanci InfluxDB.

Vytvoření databáze
Nyní už pokračujeme jednoduchými databázovými příkazy:
SHOW DATABASES, který nám vypíše dostupné databáze. Následně pak tím nejdůležitějším, tedy vytvořením naší nové databáze, kterou pak budeme plnit daty:CREATE DATABASE jméno(v našem případě např.CREATE DATABASE telegraf)- Pro kontrolu použijeme opět příkaz
SHOW DATABASES
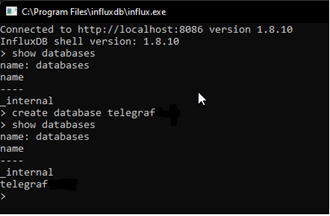
Nyní tedy máme připravenou databázi, abychom ji následně plnili daty, které posbírá Telegraf.
Instalace Telegrafu
Instalace Telegrafu je otázkou pouze stažení, vytvoření dedikované složky a následné instalace aplikace jako systémové služby.
Jako první krok je nutné stáhnout si software Telegraf.
- Přejdeme tedy na následující odkaz: https://portal.influxdata.com/downloads/
- Vybereme aktuální verzi Telegrafu a námi požadovanou platformu.
- Následně už jen stačí soubory rozbalit do vhodné složky.
Doporučují soubory rozbalit do složky Program Files, kde si vytvoříme složku s názvem Telegraf. - Samotnou instalaci pak provedeme tak, že spustíme příkazový řádek, přejdeme do zvolené složky s umístěním (v našem případě
C:/Program Files/Telegraf/) - A následně spustíme příkaz:
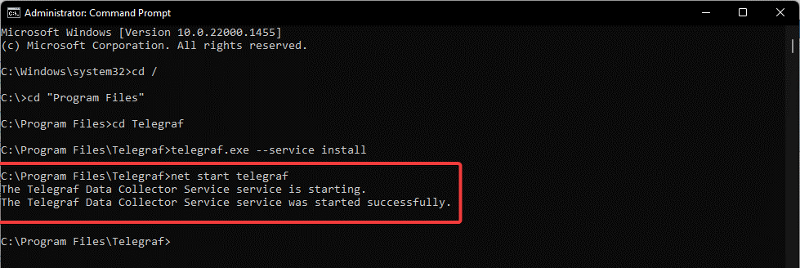
C:/Program Files/Telegraf/telegraf.exe --service install - Tímto nainstalujeme software Telegraf jako službu.
- Pro ověření a spuštění služby pak použijeme příkaz:
net start telegraf
Konfigurace Telegrafu
Výchozí konfigurační soubor Telegrafu je součásti staženého instalačního balíčku. Je však nutné jej upravit podle vlastních potřeb.
Jedná se o soubor „telegraf.conf“, který je umístěn ve složce společně s „telegraf.exe“.
Veškerá nastavení jsou v něm rozepsána a také docela smysluplně vysvětlena. Některá nastavení jsou zakomentovány pomocí znaku #, který je nutno odstranit, pokud chceme dané nastavení použít.
Nás bude nejvíce zajímat sekce výstupů (“Outputs”), kde nastavíme místo pro ukládání nasbíraných dat a sekce vstupů (“Inputs”), kde naopak nastavíme, jaká data chceme sbírat.
Output
V této sekci je zapotřebí nastavit, kam máme odesílat data, tedy specifikovat naši existující databázi InfluxDB.
V našem případě je řešení běžící na serveru, jako výstup máme tedy uvedenou adresu instance InfluxDB.
Je tedy zapotřebí specifikovat adresu, kde databáze běží. Pokud instance běží na “lokálu” (tedy stejném počítači), bude adresa „urls = ["http://127.0.0.1:8086"]“
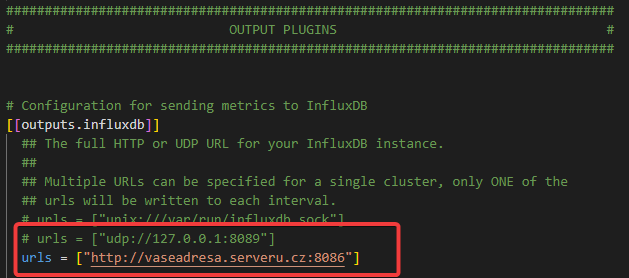
Nejdůležitější položkou této sekce je tedy nakonfigurování správné databáze, kam chceme sbírat data a následně specifikace, kde je náš výstup.
[[outputs.influxdb]]
urls = ["http://Your-Server-IP:8086"] # required.
database = "telegraf" # required.Input
Sekce „input“ slouží k vymezení oblastí dat, která chceme monitorovat a provádět jejich sběr.
Musíme si tedy rozmyslet, co chceme monitorovat. Konfigurace jako taková už obsahuje velkou řadu předdefinovaných čítačů (counters), které můžeme jednoduše použít. Stačí dané řádky „odkomentovat“ a začít využívat, co potřebujeme.
Jednotlivé čítače se chovají obdobně jako v programu Windows Performance Monitor. Jejich pojmenování je stejné a jsou rozděleny i do stejných sekcí.
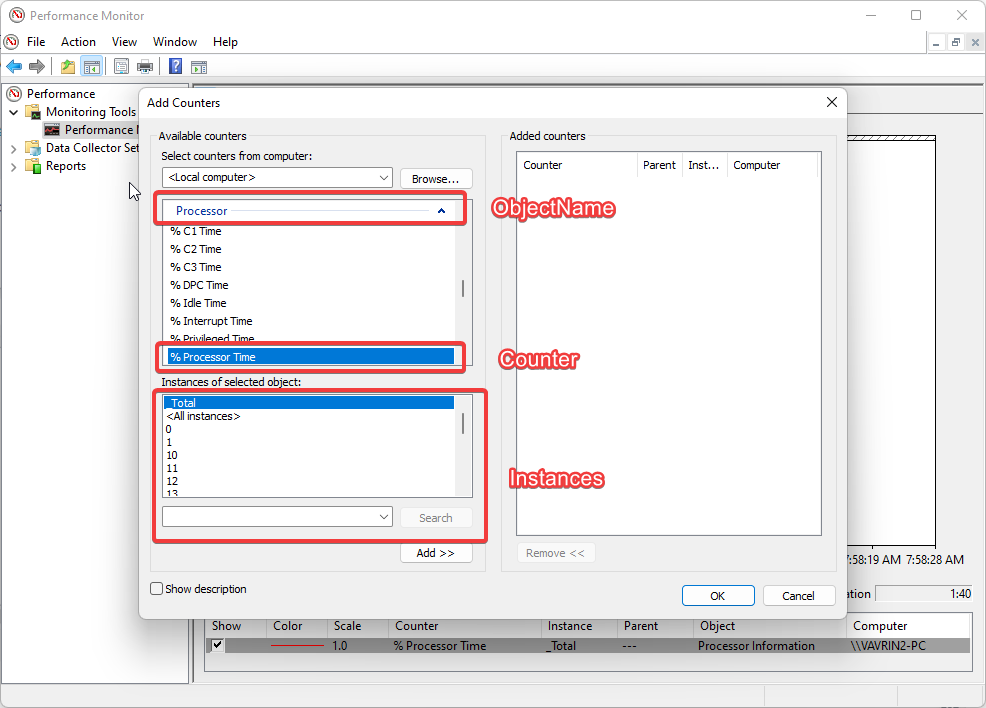
Vysvětlíme si na obrázku níže:
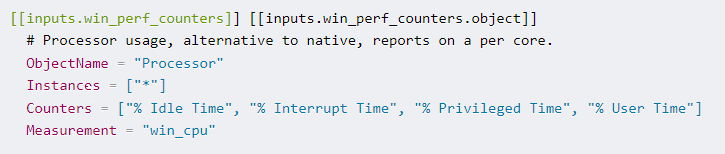
Vidíme popis čítače pro objekt „Processor“ a jednotlivé čítače poté představují položky jako jsou „% Idle Time“, „% Interupt Time“ atd.
Pokud chceme přidat například čítač pro procesorový čas, přidáme jednoduše do konfigurace telegrafu mezi „Counters“ ještě položku „% Processor Time“.
Položka a přepis: „Instances = ["*"]“ znamená, že chceme vybrat veškeré běžící instance nikoliv například přesně definovat jednotlivé běžící služby.
Pro vysvětlení obrázek z Windows Performance Monitoru.
General (Agent)
Tato sekce nám poslouží především ke konfiguraci obecných nastavení pro Telegraf.
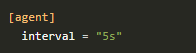
Zde lze nastavit například interval sběru dat, což je pro nás jeden z nejdůležitějších údajů.
Také můžeme nastavit například velikost bufferu apod.
metric_buffer_limit = 10000
metric_batch_size = 1000Pokud chceme nastavit i logování, je nutno specifikovat cestu k souboru s logem a také další parametry pro logování.
I takto minimalisticky upravená konfigurace je pro naše účely zcela postačující. Pro další úpravy můžeme využít webových stránek Telegrafu, kde je celá konfigurace dobře dokumentována.
Nyní jsme tedy připraveni pro sběr dat a náš Telegraf již začíná monitorovat výkon našeho systému.
Zobrazení výsledků pomocí Grafany
V dalším pokračování se podíváme na nastavení Grafany, pomocí které jednotlivé výsledky velmi elegantně zobrazíme, a budeme tak schopni v reálném čase vidět, jak vypadá výkon našeho systému.
Můžeme tak velmi efektivně monitorovat, jaký vliv na náš systém mají jednotlivé programy, služby, či cokoliv dalšího, co nás zajímá.